数据集来源于中国科学院自动化研究所制作的手写汉字数据集HWDB1.1,该数据集包含3755个不同的汉字,共122万张汉字图像。本次选取其中的100个汉字作为数据集。
项目目录包含3个文件夹,分别是code、data和tmp。所有原始数据存放在data文件夹中。
源代码
源代码
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from torchsummary import summary# ===================== 4.2 加载数据 =====================
# 4.2.1 定义生成图像集路径文档的函数
def classes_txt(root, out_path, num_class=None):# 列出根目录下所有类别所在的文件夹名dirs = os.listdir(root)# 如不指定类别数量,则读取所有if not num_class:num_class = len(dirs)# 如果输出文件路径不存在就新建一个if not os.path.exists(out_path):with open(out_path, 'w') as f:f.close()# 如果文件中本来就有一部分内容,只需要补充剩余部分;如果数据类别数多则跳过with open(out_path, 'r+') as f:try:end = int(f.readlines()[-1].split('/')[-2]) + 1except:end = 0if end < num_class - 1:dirs.sort()dirs = dirs[end:num_class]for dir in dirs:files = os.listdir(os.path.join(root, dir))for file in files:f.write(os.path.join(root, dir, file) + '\n')# 4.2.2 定义读取并转换图像数据格式的类
class MyDataset(Dataset):def __init__(self, txt_path, num_class, transforms=None):super(MyDataset, self).__init__()# 存储图像的路径self.images = []# 图像的类别名self.labels = []# 打开生成的TXT文档with open(txt_path, 'r') as f:for line in f:# 只读取前num_class个类if int(line.split('\\')[-2]) >= num_class:breakline = line.strip('\n')self.images.append(line)self.labels.append(int(line.split('\\')[-2]))# 图像格式转换self.transforms = transformsdef __getitem__(self, index):# 用PIL.Image读取图像image = Image.open(self.images[index]).convert('RGB')label = self.labels[index]if self.transforms is not None:# 进行格式转换image = self.transforms(image)return image, labeldef __len__(self):return len(self.labels)# 4.2.3 加载图像数据
# 数据集根路径
root = r'C:\Users\黄楚玉\Desktop\杂七杂八\手写汉字识别\data'
# 生成训练集、测试集路径TXT
classes_txt(os.path.join(root, 'train'), os.path.join(root, 'train.txt'), 100)
classes_txt(os.path.join(root, 'test'), os.path.join(root, 'test.txt'), 100)# 设置设备(CUDA/CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 图像预处理:resize为64*64、转灰度图、转Tensor
transform = transforms.Compose([transforms.Resize((64, 64)),transforms.Grayscale(),transforms.ToTensor()
])# 加载训练集和测试集
train_set = MyDataset(os.path.join(root, 'train.txt'), num_class=100, transforms=transform)
test_set = MyDataset(os.path.join(root, 'test.txt'), num_class=100, transforms=transform)# 放入数据加载器
train_loader = DataLoader(train_set, batch_size=50, shuffle=True)
test_loader = DataLoader(test_set, batch_size=5473, shuffle=True)# 提取测试集数据(取第二批500张测试)
for step, (x, y) in enumerate(test_loader):test_x, labels_test = x.to(device), y.to(device)break# ===================== 4.3 构建网络 =====================
class MYNET(nn.Module):def __init__(self):super(MYNET, self).__init__()# 卷积层+池化层self.conv1 = nn.Conv2d(1, 6, 3)self.conv2 = nn.Conv2d(6, 16, 5)self.pool = nn.MaxPool2d(2, 2)# 全连接层self.fc1 = nn.Linear(2704, 512)self.fc2 = nn.Linear(512, 84)self.fc3 = nn.Linear(84, 100)def forward(self, x):# 卷积+激活+池化x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))# 展平x = x.view(-1, 2704)# 全连接层x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 初始化模型并查看结构
model = MYNET().to(device)
summary(model, (1, 64, 64))# ===================== 4.4 编译网络 =====================
# 优化器(Adam,学习率0.001)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 损失函数(交叉熵损失,适用于分类任务)
loss_func = nn.CrossEntropyLoss()# ===================== 4.5 训练网络 + 4.6 性能评估 =====================
EPOCH = 3
# 训练循环
for epoch in range(EPOCH):for step, (x, y) in enumerate(train_loader):# 数据送入设备picture, labels = x.to(device), y.to(device)# 前向传播output = model(picture)# 计算损失loss = loss_func(output, labels)# 反向传播+优化optimizer.zero_grad()loss.backward()optimizer.step()# 每50个批次进行性能评估if step % 50 == 0:# 测试集前向传播test_output = model(test_x)# 计算预测结果pred_y = torch.max(test_output, 1)[1].data.squeeze()# 计算准确率accuracy = (pred_y == labels_test).sum().item() / labels_test.size(0)# 打印信息print(f'迭代次数: {epoch} | 训练损失: {loss.data:.4f} | 测试准确率: {accuracy}')print('【学号3115】完成训练')# 保存模型权重(tmp文件夹需提前创建)
tmp_path = r'C:\Users\黄楚玉\Desktop\杂七杂八\手写汉字识别\tmp'
if not os.path.exists(tmp_path):os.makedirs(tmp_path)
torch.save(model.state_dict(), os.path.join(tmp_path, '学号3115'))# ===================== 4.7 模型预测 =====================
# 图像预处理(与训练时一致)
predict_transform = transforms.Compose([transforms.Resize((64, 64)),transforms.Grayscale(),transforms.ToTensor()
])# 加载预训练模型
predict_model = MYNET()
predict_model.load_state_dict(torch.load(os.path.join(tmp_path, '学号3115')))
predict_model.eval() # 评估模式# 读取测试图像(示例:test/00008/816.png)
img_path = os.path.join(root, 'test', '00008', '816.png')
img = Image.open(img_path)
# 图像预处理
img = predict_transform(img)
img = img.view(1, 1, 64, 64)
# 模型预测
output = predict_model(img)
_, prediction = torch.max(output, 1)
prediction = prediction.numpy()[0]
# 打印预测结果
print(f'【学号3115】预测标签: {prediction}')
运行结果如下:
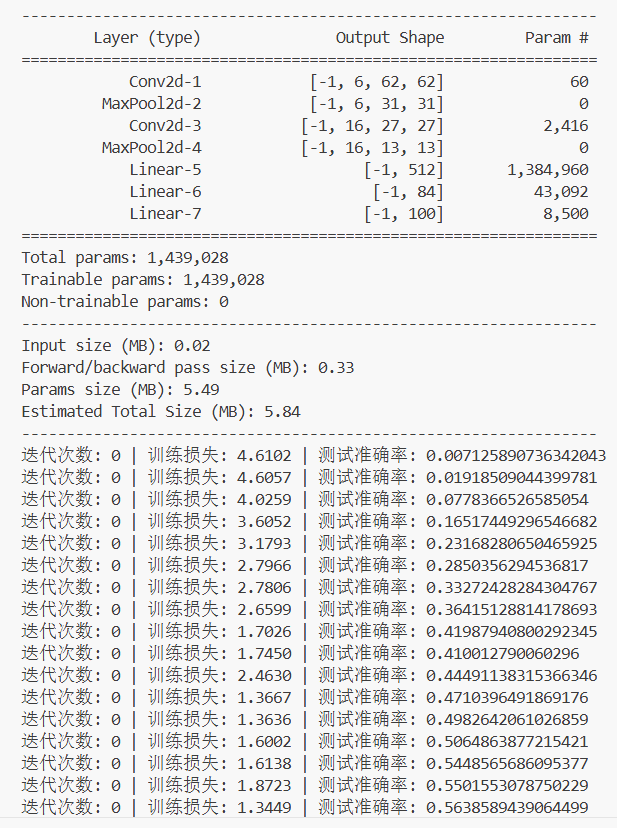 图1
图1  图2
图2  图3
图3
 图4
图4  图5
图5  图6
图6
 图7
图7  图8
图8 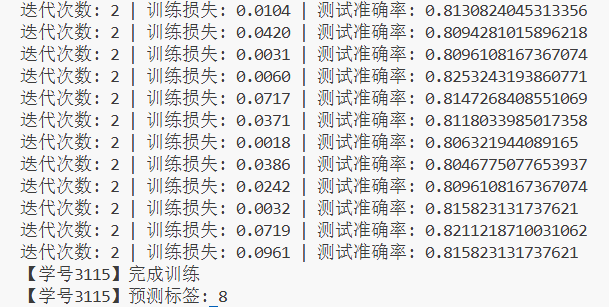 图9
图9
输出文件存放在tmp文件夹中,如模型的权重,如下图所示: