📊 统计检验里的“变异比值”逻辑
简单来说,卡方分布告诉我们“变异有多大”,而F分布告诉我们“这个变异相对于另一个变异来说,是否大到显著”。
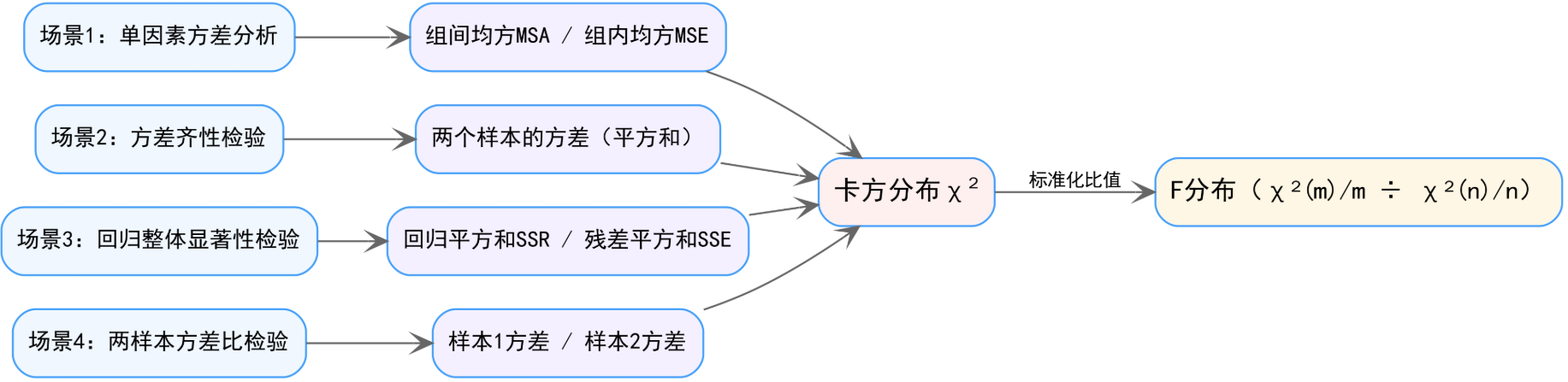
🔗 场景→平方和→卡方→F分布 关系链
✨ 一、F分布核心知识点速览
F分布是两个独立卡方分布的“标准化比值”:若随机变量 \(X \sim \chi^2(m)\)、\(Y \sim \chi^2(n)\) 且相互独立,那么
\[W = \frac{(X/m)}{(Y/n)} \sim F(m,n)
\]
- 🎯 本质:比较“两个变异来源”的相对大小(分子自由度 \(m\)、分母自由度 \(n\))。
- 📈 分布特征:正偏态(取值永远非负)、自由度决定形态(自由度越大越趋近对称)。
🧮 二、均值与方差的直观解读
F分布的均值和方差由分母自由度 \(n\) 主导,我们可以从“变异比较”的角度理解:
- 均值:\(E[F] = \frac{n}{n-2}\)(要求 \(n>2\))
- 直观上,F是两个“卡方/自由度”的比值,当分母自由度 \(n\) 足够大时,均值趋近于1。这符合“如果两个变异来源无差异,比值应接近1”的统计直觉。
- 方差:\(\text{Var}[F] = \frac{2n^2(m+n-2)}{m(n-2)^2(n-4)}\)(要求 \(n>4\))
- 方差反映F值的离散程度:分母自由度 \(n\) 越小,方差越大(分布越分散);分子自由度 \(m\) 增大时,方差也会上升,说明两个变异来源的自由度都影响F值的波动幅度。
🎯 三、F分布的典型应用场景
1. 单因素方差分析(ANOVA)
- 目的:检验多组均值是否存在显著差异。
- 逻辑:将总变异拆分为组间变异(MSA)和组内变异(MSE),两者都是“卡方分布/自由度”的形式。计算 \(F = \text{MSA}/\text{MSE}\),若F值显著大于1,说明组间变异远大于组内随机变异,拒绝“各组均值相等”的原假设。
2. 方差齐性检验(Levene检验等)
- 目的:验证两个/多个总体的方差是否相等。
- 逻辑:样本方差是“卡方分布/自由度”的无偏估计,两个样本方差的比值服从F分布。若F值接近1,说明两组方差无显著差异;若偏离1较远,则认为方差不齐。
3. 回归方程整体显著性检验
- 目的:检验自变量对因变量的解释能力是否显著。
- 公式定义:
- 回归平方和(SSR):\(SSR = \sum_{i=1}^n (\hat{y}_i - \bar{y})^2\)
(\(\hat{y}_i\) 为回归模型的预测值,\(\bar{y}\) 为因变量的均值,反映自变量解释的变异) - 残差平方和(SSE):\(SSE = \sum_{i=1}^n (y_i - \hat{y}_i)^2\)
(\(y_i\) 为因变量的实际观测值,反映未被解释的随机变异)
- 回归平方和(SSR):\(SSR = \sum_{i=1}^n (\hat{y}_i - \bar{y})^2\)
- 逻辑:SSR和SSE均服从卡方分布,计算 \(F = \frac{\text{SSR}/k}{\text{SSE}/(n-k-1)}\)(\(k\) 为自变量个数),若F显著大于临界值,说明回归模型整体有效,自变量能显著解释因变量的变异。
4. 两样本方差比检验
- 目的:直接比较两个样本方差的差异是否显著。
- 逻辑:样本方差 \(s_1^2, s_2^2\) 分别是卡方分布除以自由度,比值 \(F = s_1^2/s_2^2\) 服从F分布,通过与临界值比较判断是否来自同方差总体。
❓ 四、为什么要构造“两个卡方相除”?
卡方分布本身是“平方和的分布”,包含了“变异大小”的信息,但卡方值受自由度影响(自由度越大,卡方期望越大)。为了消除自由度和量纲的影响,我们将卡方除以自由度,得到“均方”(方差的无偏估计)。
两个均方的比值(F分布)的核心作用是:
- 相对比较:关注“变异的相对大小”而非绝对大小(比如组间变异是“真实差异”还是“随机误差”,需要和组内变异比)。
- 标准化检验:F分布的概率密度是已知的,通过计算F值并与临界值比较,可进行显著性检验,判断两个变异来源的差异是否“非随机”。
简单来说,卡方分布告诉我们“变异有多大”,而F分布告诉我们“这个变异相对于另一个变异来说,是否大到显著”。
🎯 用“波动拆解”理解:解释的变异 vs 未被解释的变异
我们可以把因变量 \(y\)(比如考试成绩、体重、销售额)的整体波动看作一个“总变异蛋糕”,回归分析的本质就是把这个蛋糕切分成两部分\(SST = SSR + SSE\):
1. 先看懂“总变异”:因变量自身的波动
总变异用总平方和 SST 表示:
\[SST = \sum_{i=1}^n (y_i - \bar{y})^2
\]
它描述了所有观测值 \(y_i\) 相对于因变量均值 \(\bar{y}\) 的离散程度。
- 比如:全班学生的考试成绩从 55 分到 95 分,这个分数的整体波动就是“总变异”。
- 回归的目标:用自变量 \(x\)(比如学习时长、复习次数)来“解释”为什么有的学生分数高、有的分数低。
2. ✅ 回归平方和(SSR):自变量“解释了”的变异
\[SSR = \sum_{i=1}^n (\hat{y}_i - \bar{y})^2
\]
这里的 \(\hat{y}_i\) 是回归模型通过自变量 \(x\) 预测出的 \(y\) 值。
- 直观理解:
假设我们用“学习时长”预测“考试成绩”,发现“学习10小时的学生平均成绩比全班均值高15分”,这15分的差异是“学习时长”这个自变量能解释的——因为学习时间长→成绩更高,这部分可解释的波动就是SSR。 - 统计意义:
SSR 反映了“因变量的波动中,和自变量变化相关的部分”。自变量和因变量的关联越强,SSR 就越大,说明模型能解释的变异越多。
3. ❌ 残差平方和(SSE):自变量“解释不了”的变异
\[SSE = \sum_{i=1}^n (y_i - \hat{y}_i)^2
\]
这里的 \(y_i - \hat{y}_i\) 是“残差”,即实际观测值和模型预测值的差距。
- 直观理解:
同样是“学习10小时”,A学生考了90分,B学生只考了75分——这15分的差距无法用“学习时长”解释,可能是因为A考试当天状态更好、B刚好遇到不会的题,这类随机因素导致的波动就是SSE。 - 统计意义:
SSE 是模型“没接住”的波动,代表了随机误差、遗漏的自变量(比如“学习效率”)、测量误差等无法被当前模型解释的变异。SSE 越小,说明模型对数据的拟合越紧密。
🔍 用“身高→体重”的例子彻底搞懂
假设我们想通过“身高”解释“体重”的变异:
- 总变异(SST):所有人的体重从40kg到90kg的整体差异。
- 解释的变异(SSR):身高从150cm到180cm对应的体重变化(比如身高每增加10cm,体重平均增加5kg),这部分是“身高”能解释的体重差异。
- 未被解释的变异(SSE):同样身高170cm的人,有的体重60kg、有的70kg——这部分差异来自“健身习惯、饮食、基因”等未纳入模型的因素,属于随机误差。
💡 延伸:解释力的量化指标 \(R^2\)
\[R^2 = \frac{SSR}{SST} = 1 - \frac{SSE}{SST}
\]
\(R^2\) 直接反映了“自变量能解释的变异占总变异的比例”:
- \(R^2 = 0.8\) → 80% 的因变量波动可以用自变量解释,模型拟合效果好。
- \(R^2 = 0.2\) → 仅20%的波动能被解释,模型需要优化(比如加入更多自变量)。