BeautifulSoup
蔬菜网
(完整代码再文后)
首先再基础的部分,和re正则不同的是,我们要先对拿到的网页源代码进行解析。
接着我们观察一下源代码,这里我们要爬的是网页中蔬菜的价格。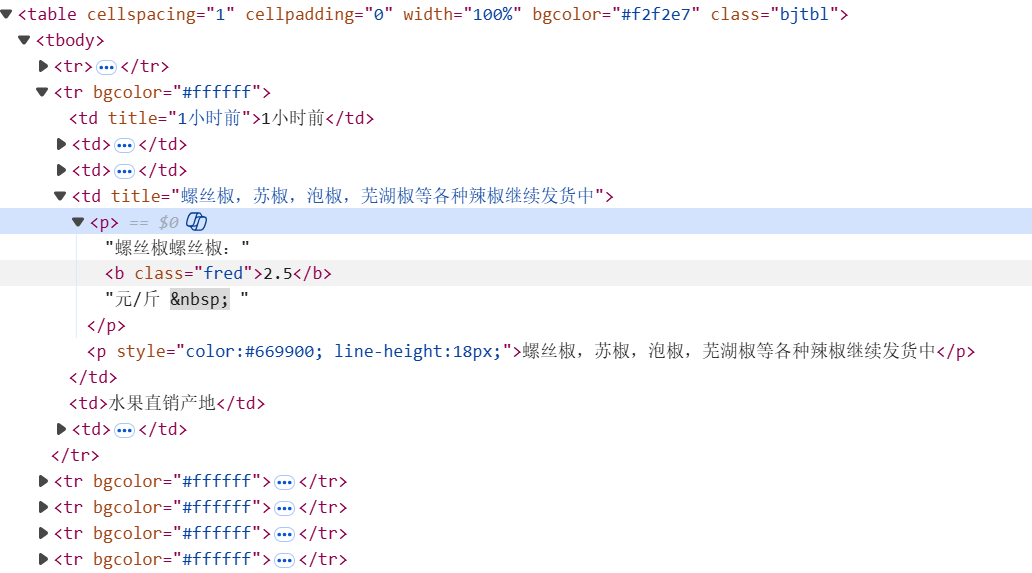
我们可以发现所有的价格品类等信息都在table标签下面,我们可以用beautifulsoup语句提取这个标签下所有的内容,这里我们选取class="bjtbl"作为选取条件的属性和属性值(如果别的没有重复也可以用别的)
<table cellspacing="1" cellpadding="0" width="100%" bgcolor="#f2f2e7" class="bjtbl">

选取完之后打印看一下效果,但是我们发现第一行的报价日期、产地、类别等字样也被收集进来了,这时候我们,观察网页源代码可以发现第一行的内容也在table标签下,也被收入进来了,那我们在进行再一次筛选的时候需要剔除第一行的项目。
tr代表了一行数据,我们把每一行数据提取出来,再在循环中提取各项不同数据,代码如上。最后去除第一行废弃数据。
我们继续观察网页源代码,td代表的是一列数据,第一列存储的是报价的时间,第二列是产地,第三列是类别,第四列存储了具体的品种和价格和一些补充信息,第五列则是联系人的方式,我们按照列表的方法把数据提取并写入文件。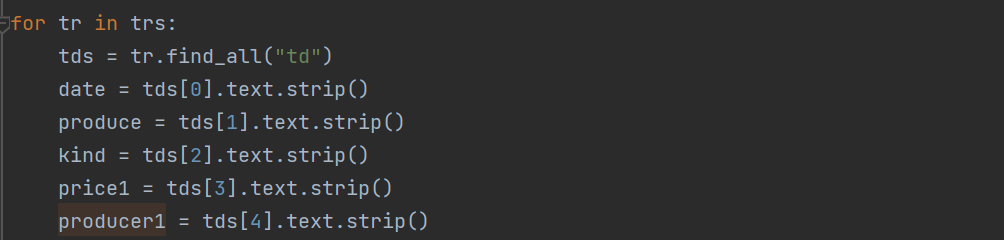
但是打开文件后我们发现,中间有很多[NBSP]存在,这里表示这里有空格,所以我们还要对price和produce做一个空格置换的处理。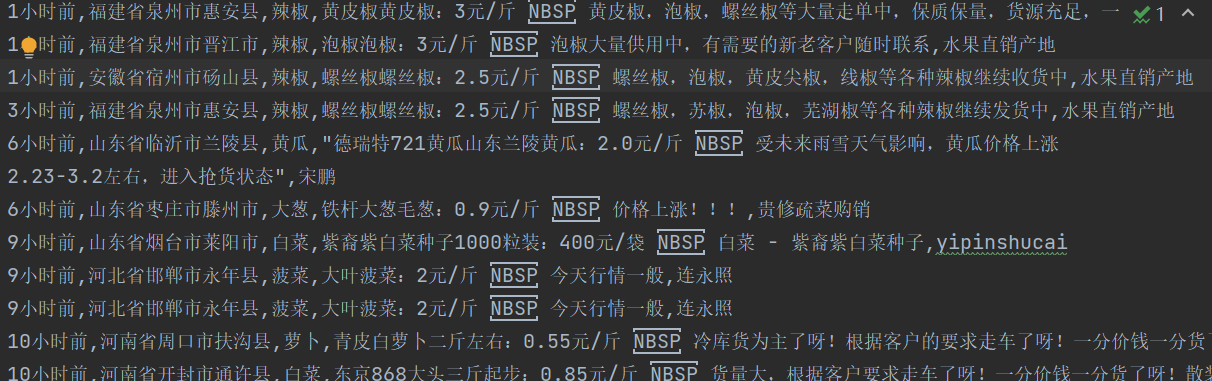
对于提取到的第三列第四列数据,把前后非断行的空格符换成空重新写入文档中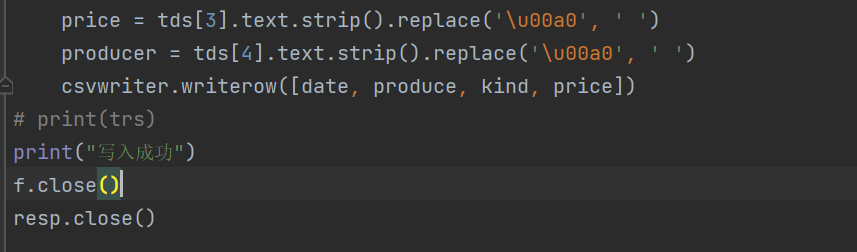
别忘记关上文档和访问!
from bs4 import BeautifulSoup
import requests
import csvurl = "http://www.shucai123.com/price/"
header = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
f = open("蔬菜网价格.csv", "w", encoding="utf-8", newline="")
csvwriter = csv.writer(f) # 写入csv文件
resp = requests.get(url, headers=header)page = BeautifulSoup(resp.text, "html.parser") # 解析网页,html.parser为解析器
table = page.find_all("table", attrs={"class": "bjtbl"})
# print(table)
trs = table[0].find_all("tr")[1:] # 去掉表头for tr in trs:tds = tr.find_all("td")date = tds[0].text.strip()produce = tds[1].text.strip()kind = tds[2].text.strip()price = tds[3].text.strip().replace('\u00a0', ' ')producer = tds[4].text.strip().replace('\u00a0', ' ')csvwriter.writerow([date, produce, kind, price])
# print(trs)
print("写入成功")
f.close()
resp.close()摄影中国
(完整代码附在文后)
老规矩先观察源代码
我们可以发现图片和连接都被存在li中,这里也有图,但这里的图是缩略图,我们不采用。一个ul则是存储一行的信息,而所有的ul则存储在

这里因为我用的python版本原因,哪怕只读取到一个数据,也必须使用列表[0]的形式
接着我们进入列表循环,从每一个a标签的href中拿到链接,这里使用get方法

拿到并访问下一级网址后,我们继续观察网页源代码,使用开发者工具,找到图片在源代码中的位置。发现他在img标签下,我们用属性和属性值做进一步确定,防止提取错误
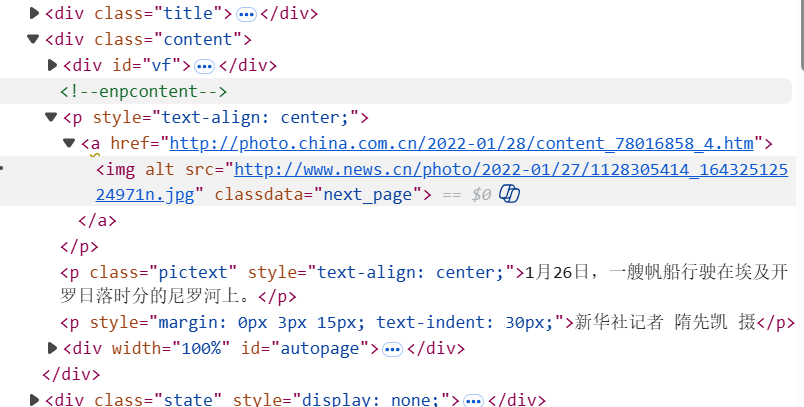

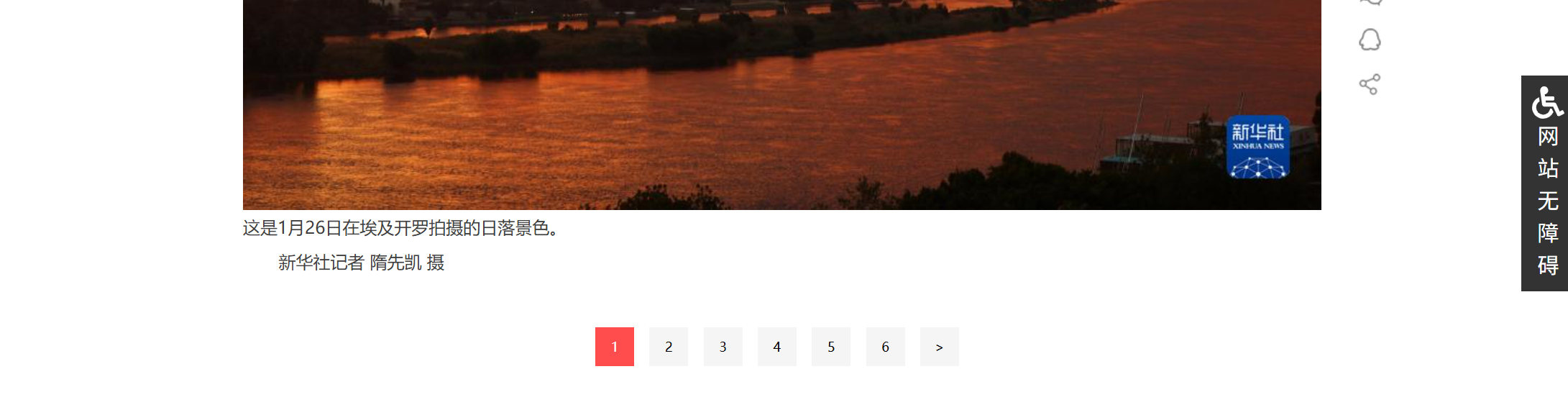
但是这样只读取到了第一页,那后面几页怎么办呢,我们观察后面的几页的连接
http://photo.china.com.cn/2022-01/28/content_78016858_3.htm
在url后面拼接_page来转页,详细可以看之前豆瓣的方法,用status_code去做验证,但这里我们用另一种办法,我们发现当page为1时页面不存在,接着尝试page为0神奇的事情发生了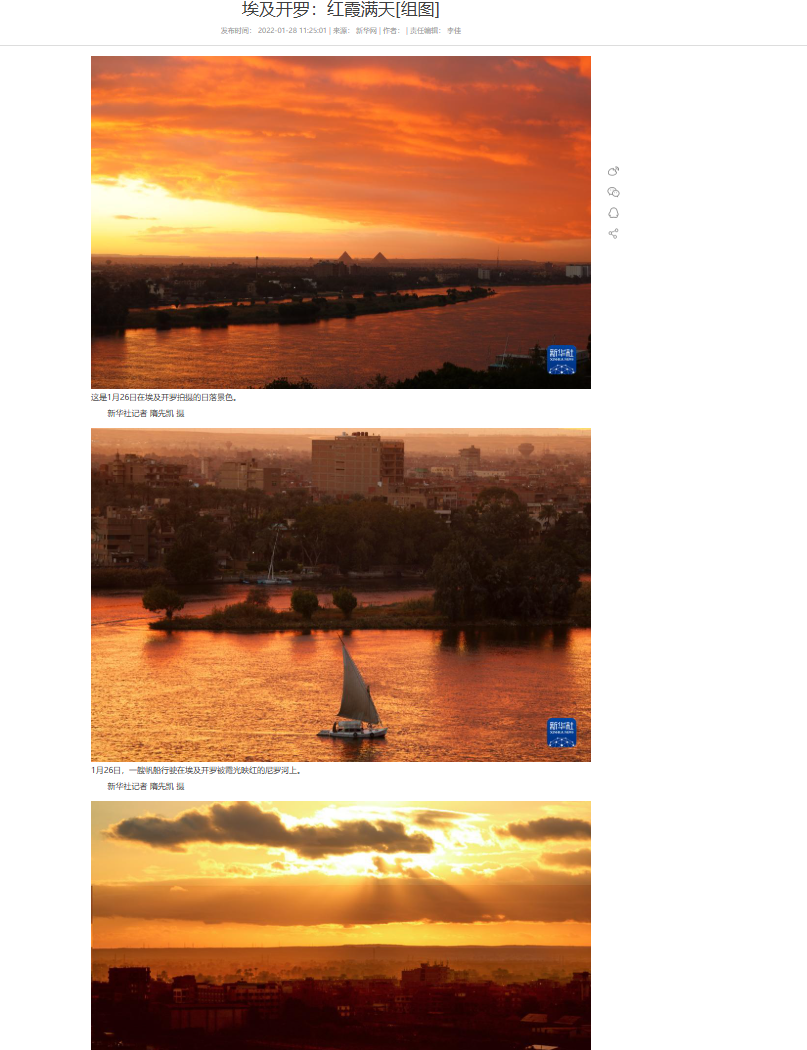
所有的图片都出现了,那我们可以直接拼接_0然后从中一次提取所有的图片url,别忘记在一次提取结束加上sleep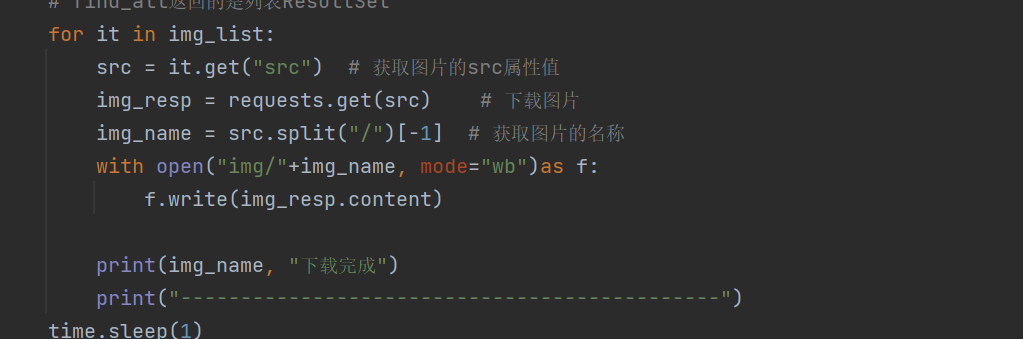
好了这下我们就获取了所有图片
import requests
from bs4 import BeautifulSoup
import time
from urllib.parse import urljoin
url = "http://photo.china.com.cn/foto/node_7185699.htm"
header = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
response = requests.get(url, headers=header)
response.encoding = "utf-8"main_page = BeautifulSoup(response.text, "html.parser") # 解析网页
alist = main_page.find_all("div", class_="main")
alist1 = alist[0].find_all("li")for a in alist1:# 获取图片链接a_href = a.find("a")href = a_href.get("href") # 通过get方法获取href属性的值href = href.replace(".htm", "_0.htm")child_page_response = requests.get(href)child_page_response.encoding = "utf-8"child_page = BeautifulSoup(child_page_response.text, "html.parser")img_list = child_page.find_all("img", attrs={'classdata': 'next_page'})# find_all返回的是列表ResultSetfor it in img_list:src = it.get("src") # 获取图片的src属性值img_resp = requests.get(src) # 下载图片img_name = src.split("/")[-1] # 获取图片的名称with open("img/"+img_name, mode="wb")as f:f.write(img_resp.content)print(img_name, "下载完成")print("---------------------------------------------")time.sleep(1)print("over!!")
response.close()