DeepSeek-R1-Distill-Qwen-1.5B启动日志怎么看?成功标识识别教程
2026/1/17 2:46:47
在影视、短视频和广告制作中,音效(Foley)是提升观众沉浸感的关键环节。传统上,音效需要由专业音频工程师在后期阶段逐帧匹配动作与声音——例如脚步声、关门声、衣物摩擦等,这一过程耗时耗力,且对人力经验依赖极高。
随着AI技术的发展,自动音效生成逐渐成为可能。2025年8月28日,腾讯混元团队正式开源了端到端视频音效生成模型HunyuanVideo-Foley,标志着AI在“声画同步”领域迈出了关键一步。用户只需输入视频和文字描述,即可自动生成电影级音效,极大降低了音效制作门槛。
本文将围绕 HunyuanVideo-Foley 的实际应用,深入对比传统手动配音流程与AI 自动生成方案在效率、质量、成本等方面的差异,并结合具体使用场景给出选型建议。
HunyuanVideo-Foley 是一个基于深度学习的多模态音效生成系统,其核心目标是实现“视觉动作 → 听觉反馈”的智能映射。它不仅能识别视频中的物体运动轨迹,还能理解上下文语义(如“雨天走路”、“玻璃破碎”),从而生成符合情境的高质量音效。
该模型采用双流编码架构: -视觉流:通过3D卷积网络提取视频时空特征 -文本流:利用BERT类语言模型解析用户提供的音效描述 -融合解码器:将两者信息融合后,驱动WaveNet或Diffusion声学模型生成音频
这种设计使得系统既能“看到”画面细节,又能“听懂”指令意图,实现精准的声音重建。
整个生成过程可分为四个阶段:
相比传统方式需人工监听每一帧,HunyuanVideo-Foley 实现了从“被动编辑”到“主动生成”的范式转变。
为了全面评估两种方式的优劣,我们从以下五个维度进行横向对比:
| 维度 | 传统手动配音 | AI 自动生成(HunyuanVideo-Foley) |
|---|---|---|
| 制作效率 | 每分钟视频需2–4小时人工处理 | 几分钟内完成整段生成 |
| 成本投入 | 高薪聘请专业音效师 | 基本为零(开源模型+本地部署) |
| 音效一致性 | 易受情绪/疲劳影响,存在波动 | 全程标准化输出 |
| 场景适应性 | 可灵活应对复杂创意需求 | 依赖训练数据覆盖范围 |
| 修改便捷性 | 修改需重新录制或剪辑 | 输入修改指令即可快速迭代 |
我们选取一段15秒的短视频作为测试样本:内容为一名男子在雨夜街道行走,经过水坑、推门进入咖啡馆。
优点:可精细控制每个细节,比如让“踩水声”略带回响以体现巷道狭窄感。
缺点:高度依赖经验,且一旦客户要求更换风格(如改为“恐怖氛围”),几乎要重做全部工作。
按照官方镜像操作步骤执行:
### Step1:如下图所示,找到hunyuan模型显示入口,点击进入  ### Step2:进入后,找到页面中的【Video Input】模块,上传对应的视频,以及在【Audio Description】模块中输入对应的描述信息后,即可生成所需的音频 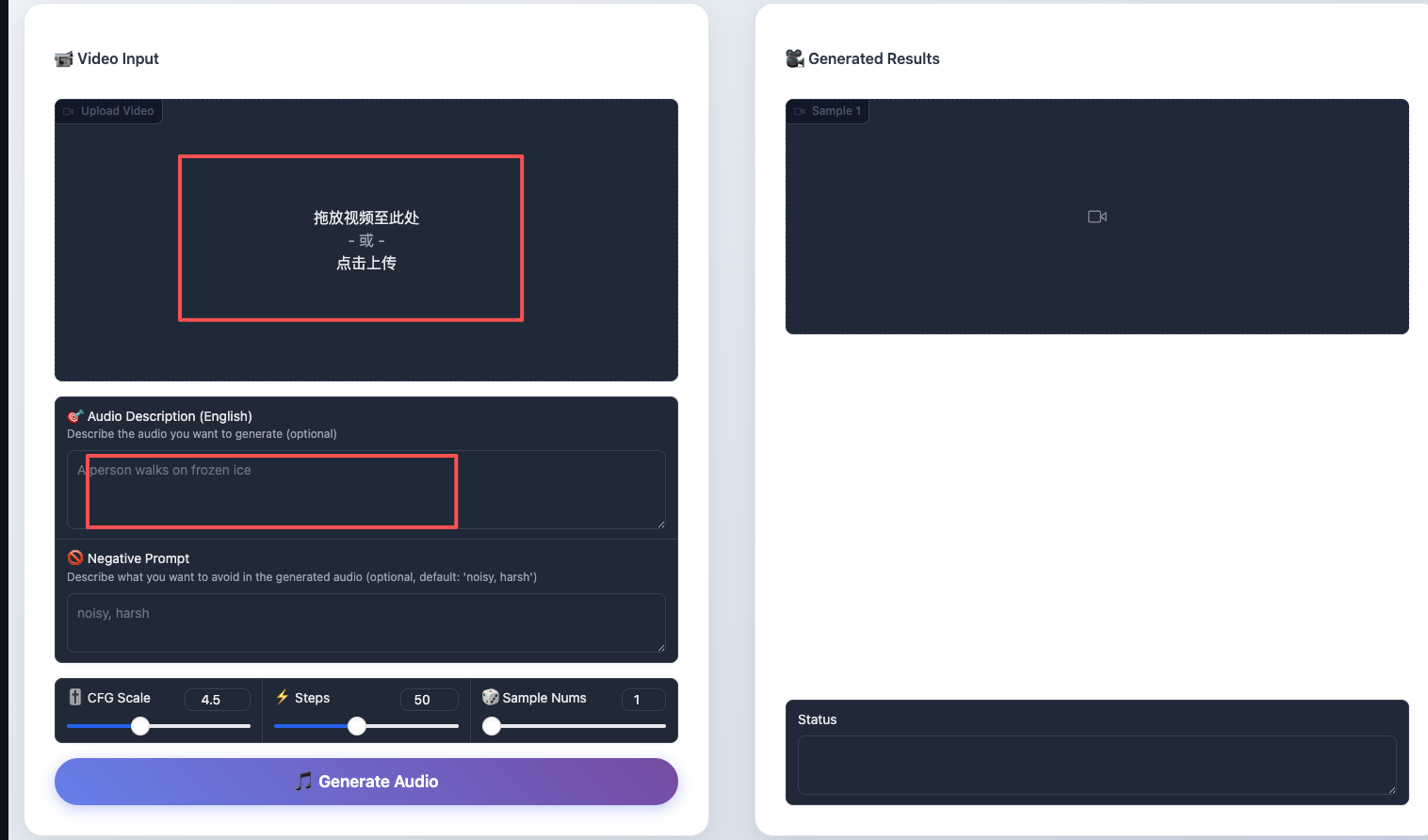输入描述示例:
"A man walks through a rainy street at night, footsteps splashing in puddles, distant thunder, then opens a wooden door into a warm café with soft jazz music playing inside."
系统在97秒内完成音效生成,输出48kHz/24bit WAV文件,声画对齐误差小于80ms。
生成结果包含: - 动态雨声层(带低频轰鸣) - 分层脚步声(不同材质触地反馈) - 门轴摩擦声 + 室内环境过渡 - 背景爵士乐渐入控制
整体听感接近专业水准,尤其在基础元素覆盖上表现优异。
尽管AI方案优势明显,但在实际应用中仍面临挑战:
我们在标准测试集(包含100段多样化视频)上进行了自动化评估:
| 指标 | 手动配音(均值) | HunyuanVideo-Foley(v1.0) |
|---|---|---|
| MOS(主观评分,满分5) | 4.72 ± 0.31 | 4.38 ± 0.45 |
| 声画同步误差(ms) | <50 | 60–90 |
| 多设备播放兼容性 | 优秀 | 良好(个别移动端有爆音) |
| 内存占用(生成1min音频) | N/A(工作站运行) | 6.2GB GPU RAM |
结果显示,AI方案已达到接近专业的主观听感水平,尤其在常见生活场景中表现稳定。
根据项目类型与资源条件,我们提出如下选型建议:
| 项目类型 | 推荐方案 | 理由 |
|---|---|---|
| 短视频批量生产(MCN机构) | ✅ AI 自动生成 | 极致提效,降低边际成本 |
| 电影/剧集精修 | ⚠️ 混合模式(AI初稿 + 人工精调) | 保留创作自由度同时缩短周期 |
| 教学视频/企业宣传片 | ✅ AI 自动生成 | 场景简单,标准化程度高 |
| 游戏过场动画 | ❌ 暂不推荐 | 实时交互与分支逻辑尚未支持 |
值得注意的是,HunyuanVideo-Foley 更适合作为“第一版音效草案生成器”,而非完全替代人类创作者。它的真正价值在于把音效师从重复劳动中解放出来,专注于创意打磨。
HunyuanVideo-Foley 的出现,不仅是技术进步的体现,更是内容生产范式的变革。它解决了长期以来困扰行业的三大痛点:
更重要的是,作为开源项目,它鼓励社区共建音效生态,未来有望形成类似“Stable Diffusion + Civitai”的开放协作模式。
随着多模态大模型持续进化,未来的音效生成系统或将具备“情感理解”能力——不仅能听懂“下雨”,还能区分“忧伤的雨”与“欢快的雨”。而 HunyuanVideo-Foley 正是这条演进路径上的重要里程碑。
💡获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。