一、支持向量机
支持向量机(Support Vector Machines,SVM)是一种二分类模型,其核心目标是寻找一个间隔最大的超平面将不同类别的数据点分隔开。这个超平面在二维空间中是一条直线,在三维空间中是一个平面,在更高维空间则是一个超平面。
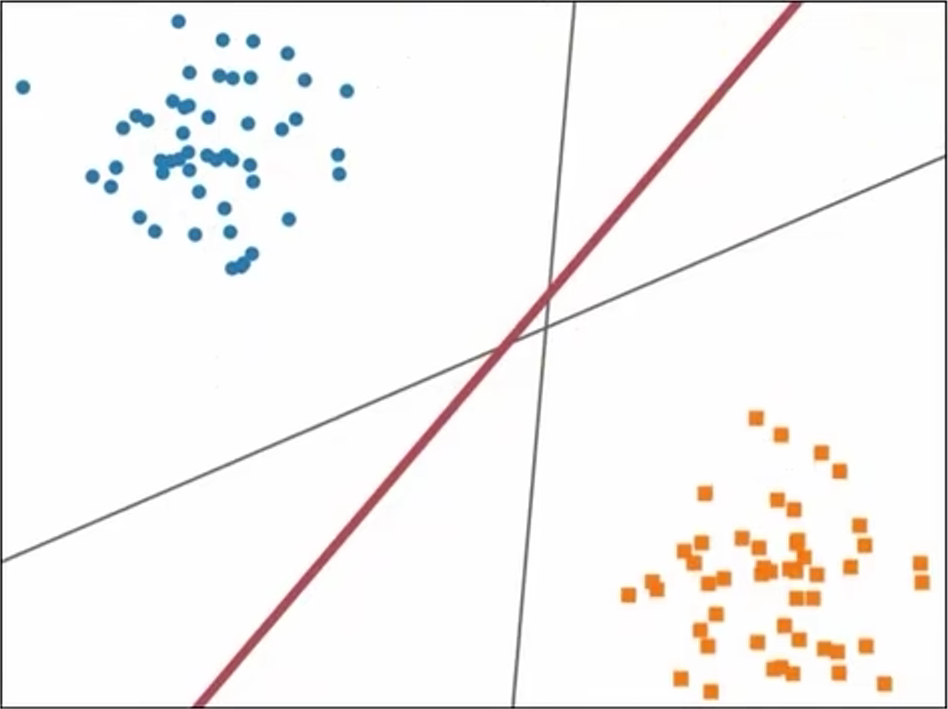
二、线性可分支持向量机
【1】、硬间隔
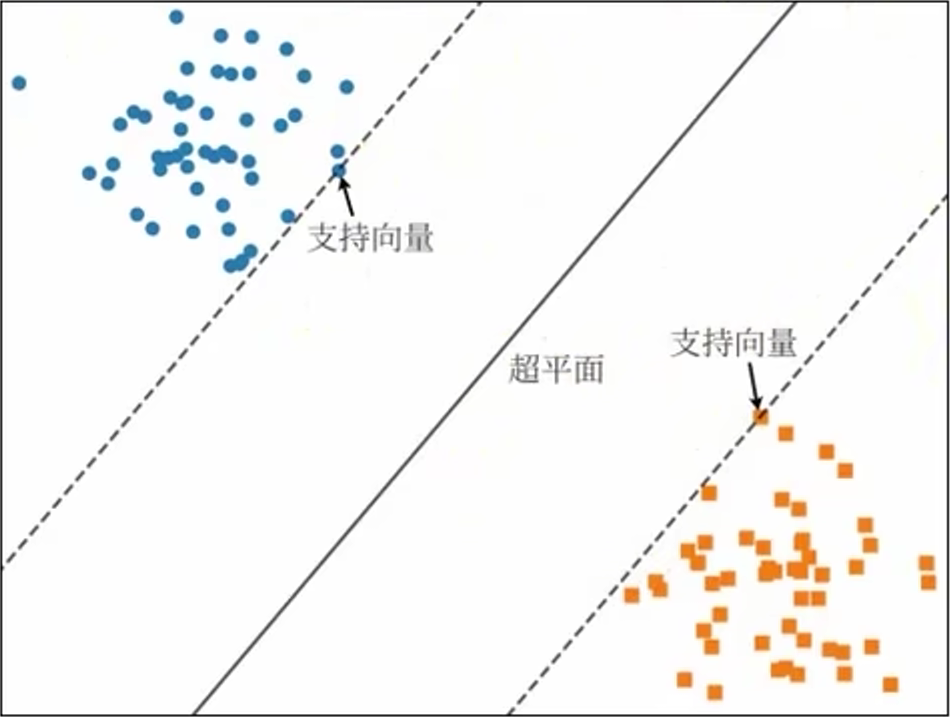
当训练样本线性可分时,此时可以通过最大化硬间隔来学习线性可分支持向量机。硬间隔是指超平面能够将不同类的样本完全划分开。距离超平面最近的几个样本点称为 支持向量,它们直接决定超平面的位置和方向,只要支持向量不变,超平面就不会变。
在样本空间中,超平面可表示为:
其中 \(\vec{w} = (w_{1}, w_{2}, ..., w_{n}\) 为 法向量,决定了 超平面的方向,b 为 位移项,决定了 超平面与原点之间的距离。将超平面记为 \((w, b)\)。相应的分类函数称为 线性可分支持向量机。
【2】、间隔与最大间隔
\(x'\) 为超平面上一点,\(w_{T}x' + b = 0\),样本空间中任一点 x 到超平面 (w, b) 的距离为:
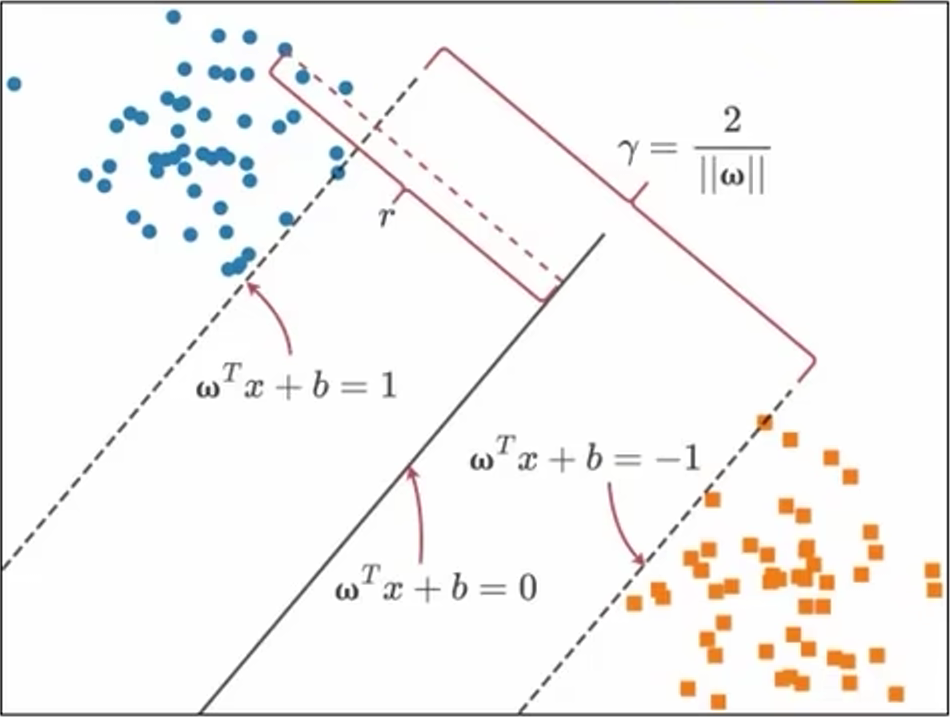
记每个样本点 \(\vec{x}_{i}\) 的类别为 \(y_{i}\) ,该样本点的函数间隔 \(\widehat{Y_{i}} = y_{i}(\vec{w}^{T}\vec{x} + b)\),表示分类预测的正确性及确信度,若超平面 (w, b) 能够将样本正确分类,则有:
此时有
观察上述公式,我们可以看出对 \(\vec{w}\), b 进行缩放 \(\vec{w} \rightarrow \lambda\vec{w}\),\(b \rightarrow \lambda b\)时,不会改变超平面,也不会改变 r 的值,但函数间隔 \(\widehat{Y}_{i} = y_{i}(\vec{w}^{T}\vec{x_{i}} + b)\) 会随着缩放 \(\vec{w}\) 和 b 而发生改变,也就是说通过缩放 \(\vec{w}\) 和 b 来任意缩放函数间隔 \(\widehat{y}_{i}\) 而不改变 \(r_{i}\)。因此,令支持向量 \(\widehat{Y_{i}} = 1\),此时支持向量到超平面的距离 \(r_{i}= \frac{\widehat{Y_{i}}}{\lvert\lvert w \rvert\rvert} = \frac{1}{\lvert\lvert w\rvert\rvert}\)。两个异类支持向量到超平面的距离之和 \(\gamma = \frac{2}{\lvert\lvert w \rvert\rvert}\),\(\gamma\) 被称为 间隔。欲找到最大间隔的超平面,也就是在约束 \(y_{i}(\vec{w}^{T}\vec{x}_{i} + b) \ge 1\) 下找到最大 \(\gamma\)。
三、线性支持向量机
先前我们假定样本在样本空间中线性可分,但现实中很可能并非如此,此时,我们无法找出一个合适的超平面将所有样本点完全正确划分。通常训练数据中会有一些特异点,如果将这些特异点去掉,剩下大部分样本点是线性可分的。这时,我们可以放宽条件,允许某些样本分错,为此,我们引入软间隔。
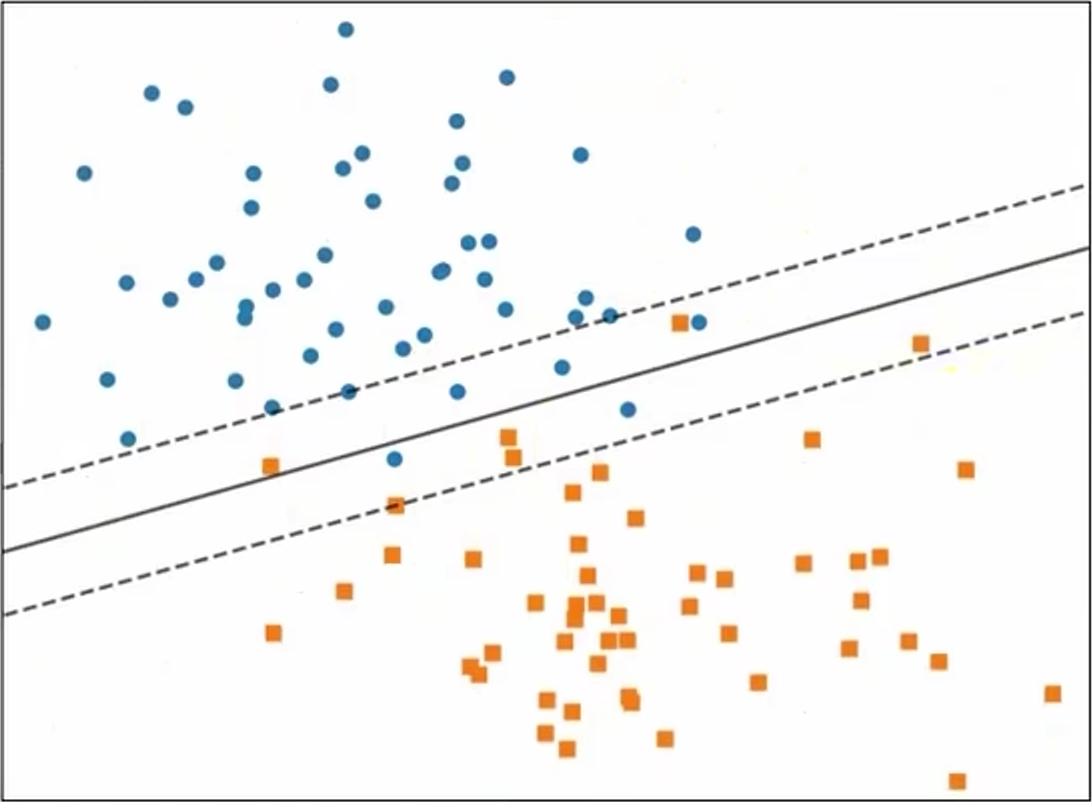
线性不可分意味着某些样本点 \((x_{i}, y_{i})\) 不能满足约束条件 \(y_{i}(\vec{w}^{T}\vec{x}_{i} + b) \ge 1\)。为解决这个问题,可以对每个样本点引入一个松弛变量 \(\xi \ge 0\),使得函数间加上松弛变量 \(\ge\) 1。这时约束条件变为:
同时,为了在最大化间隔的时候使不满足约束的样本尽可能少,目标函数中引入对误分类的惩罚:
这里 \(C > 0\) 为 惩罚系数,C 值越大对误分类的惩罚越大。
四、非线性支持向量
非线性分类问题是指通过利用非线性模型才能很好地进行分类,我们无法直接使用超平面对齐进行分类。这时,我们可以通过核函数将数据从原始空间映射到高维特征空间,使得数据在高维特征空间可分,将原本地的非线性问题转换为线性问题。使用核技学习非线性向量机等价于隐式地在高维特征空间中学习线性支持向量机。

核函数地选择也是支持向量机最大的变数,若核函数选择不合适,意味着样本映射到了一个不合适的特征空间,很可能导致性能不佳。下面是几种常用的核函数。
- 线性核:\(k(\vec{x_{i}}, \vec{x_{j}}) = \vec{x_{i}}^{T}\vec{x_{j}}\)
- 多项式核:\(k(\vec{x_{i}}, \vec{x_{j}}) = (\vec{x_{i}}^{T}\vec{x_{j}})^{d}\)
- 高斯核:\(k(\vec{x_{i}}, \vec{x_{j}}) = \exp(-\frac{\lvert\lvert\vec{x_{i}} - \vec{x_{j}}\rvert\vert^{2}}{2\sigma^{2}})\)
- 拉普拉斯核:\(k(\vec{x_{i}}, \vec{x_{j}}) = \exp(-\frac{\lvert\lvert\vec{x_{i}} - \vec{x_{j}}\rvert\rvert}{\sigma})\)
- Sigmoid 核:\(k(\vec{x_{i}}, \vec{x_{j}}) = \tanh(\beta\vec{x_{i}}^{T}\vec{x_{j}} + \theta)\)