流量统计功能文档
仓库地址:https://gitee.com/teanary/teanary_service
目录
- 功能概述
- 功能特性
- 技术架构
- 配置说明
- 使用方法
- 数据管理
- 常见问题
功能概述
流量统计功能用于统计网站前台的访问数据,包括真人访问和爬虫访问。系统会自动区分访问者类型,并记录详细的访问信息,帮助管理员了解网站的访问情况。
主要功能
- ✅ 自动统计前台访问流量
- ✅ 区分真人访问和爬虫访问
- ✅ 识别爬虫来源(Google、Bing、Baidu等)
- ✅ 缓存数据,批量写入数据库(每5分钟)
- ✅ 自动清理过期数据(默认保留90天)
- ✅ 提供统计看板和详细列表页面
功能特性
1. 智能过滤
系统会自动排除以下请求:
- ❌ 管理后台(
/manager/*) - ❌ 个人中心(
/user/*) - ❌ API 路由(
/api/*) - ❌ 静态资源(
.css,.js,.jpg,.png等) - ❌ 非 GET 请求
2. 爬虫识别
系统能够识别以下类型的爬虫:
搜索引擎爬虫:
- Google (Googlebot)
- Bing (Bingbot)
- Baidu (Baiduspider)
- Yandex (Yandexbot)
- Yahoo (Slurp)
- DuckDuckGo (Duckduckbot)
- Sogou (Sogou)
社交媒体爬虫:
- Facebook (Facebookexternalhit)
- Twitter (Twitterbot)
- LinkedIn (Linkedinbot)
- Pinterest (Pinterestbot)
其他爬虫:
- Semrush (Semrushbot)
- Ahrefs (Ahrefsbot)
- Majestic (Mj12bot)
- Dotbot
- 以及其他通用爬虫(bot、crawler、spider等)
3. 数据记录
每条流量记录包含以下信息:
- 路径 (
path): 访问的页面路径 - 方法 (
method): HTTP 方法(通常为 GET) - IP 地址 (
ip): 访问者的 IP 地址 - 用户代理 (
user_agent): 浏览器或爬虫的用户代理字符串 - 来源页面 (
referer): 来源页面的 URL - 语言 (
locale): 访问时使用的语言代码 - 是否爬虫 (
is_bot): 是否为爬虫访问 - 爬虫来源 (
spider_source): 爬虫的具体来源(如 google、bing 等) - 访问次数 (
count): 同一分钟内相同路径的访问次数 - 统计时间 (
stat_date): 统计日期(精确到分钟)
技术架构
数据流程
用户访问 → TrackTraffic 中间件 → 缓存数据 → 批量写入队列 → 数据库
核心组件
-
中间件 (
TrackTraffic)- 位置:
app/Http/Middleware/TrackTraffic.php - 功能:拦截请求,记录流量数据到缓存
- 位置:
-
批量写入任务 (
BatchWriteTrafficStatsJob)- 位置:
app/Jobs/BatchWriteTrafficStatsJob.php - 功能:每5分钟批量将缓存数据写入数据库
- 位置:
-
数据清理命令 (
CleanOldTrafficStats)- 位置:
app/Console/Commands/CleanOldTrafficStats.php - 功能:清理超过指定天数的历史数据
- 位置:
-
数据模型 (
TrafficStatistic)- 位置:
app/Models/TrafficStatistic.php - 功能:定义数据结构和查询方法
- 位置:
-
管理界面
- 统计看板:
app/Filament/Manager/Pages/TrafficStatistics.php - 详细列表:
app/Filament/Manager/Resources/TrafficStatisticResource.php
- 统计看板:
缓存机制
- 使用 Laravel Cache 存储临时流量数据
- 缓存键格式:
traffic:queue:Y-m-d-H-i - 缓存过期时间:1小时
- 每5分钟批量写入一次数据库
配置说明
1. 中间件注册
中间件已在 routes/web.php 中注册:
Route::prefix('{locale}')->middleware([SetLocaleAndCurrency::class, \App\Http\Middleware\TrackTraffic::class
])->group(function () {// 前台路由
});
2. 定时任务配置
在 routes/console.php 中已配置:
// 流量统计批量写入任务(每5分钟执行一次)
Schedule::command('app:batch-write-traffic-stats --queue')->everyFiveMinutes()->withoutOverlapping()->runInBackground();// 流量统计数据清理任务(每天凌晨2点执行,清理90天前的数据)
Schedule::command('app:clean-old-traffic-stats')->dailyAt('02:00')->withoutOverlapping();
3. 数据库表结构
表名:traffic_statistics
主要字段:
id: 主键(雪花ID)path: 访问路径(索引)method: HTTP 方法(索引)ip: IP 地址(索引)user_agent: 用户代理referer: 来源页面locale: 语言代码(索引)is_bot: 是否为爬虫(索引)spider_source: 爬虫来源(索引)count: 访问次数stat_date: 统计时间(索引,精确到分钟)
使用方法
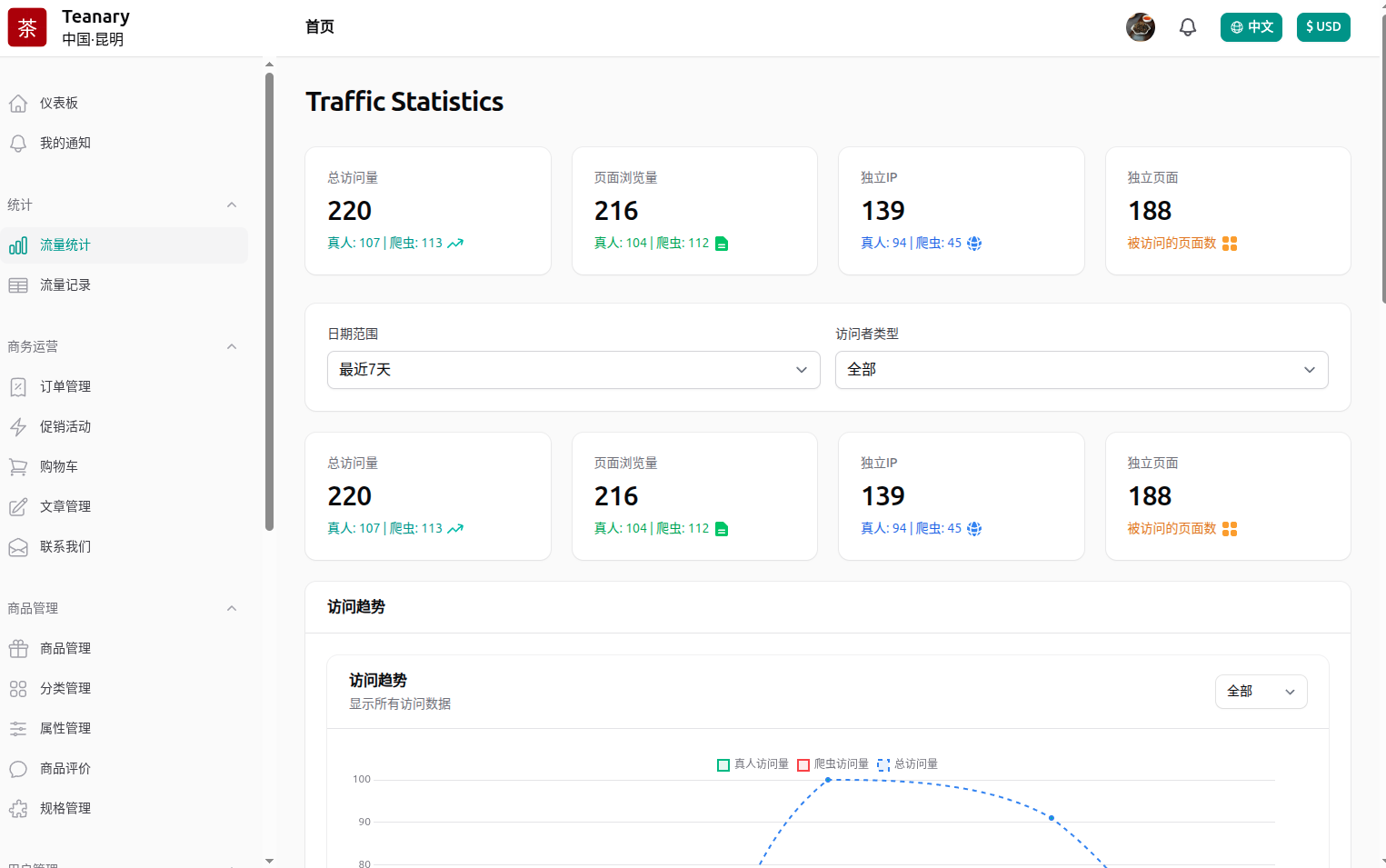
1. 查看统计看板
- 登录管理后台
- 导航到 统计 → 流量统计看板
- 可以查看:
- 总访问量、页面浏览量、独立IP、独立页面
- 真人访问和爬虫访问的对比
- 热门页面 Top 20
- 支持筛选:
- 日期范围:今天、昨天、最近7天、最近30天、最近90天
- 访问者类型:全部、真人访问、爬虫访问
2. 查看详细列表
- 登录管理后台
- 导航到 统计 → 流量明细
- 可以查看每条访问记录的详细信息
- 支持筛选:
- 访问类型(真人/爬虫)
- 爬虫来源
- 日期范围
3. 手动触发批量写入
如果需要立即将缓存数据写入数据库,可以执行:
php artisan app:batch-write-traffic-stats
4. 手动清理数据
清理超过指定天数的数据:
# 清理90天前的数据(默认)
php artisan app:clean-old-traffic-stats# 清理30天前的数据
php artisan app:clean-old-traffic-stats --days=30# 清理180天前的数据
php artisan app:clean-old-traffic-stats --days=180
数据管理
数据保留策略
- 默认保留时间:90天
- 清理时间:每天凌晨2点自动执行
- 清理方式:分批删除,每批1000条记录
数据统计方法
获取指定时间范围内的统计数据
use App\Models\TrafficStatistic;
use Illuminate\Support\Carbon;// 获取最近7天的所有数据
$startDate = Carbon::today()->subDays(6);
$endDate = Carbon::today()->endOfDay();
$stats = TrafficStatistic::getStatsByDateRange($startDate, $endDate);// 只获取真人访问数据
$humanStats = TrafficStatistic::getStatsByDateRange($startDate, $endDate, false);// 只获取爬虫访问数据
$botStats = TrafficStatistic::getStatsByDateRange($startDate, $endDate, true);
获取热门页面
// 获取最近7天的热门页面 Top 10
$topPages = TrafficStatistic::getTopPages($startDate, $endDate, 10);// 只获取真人访问的热门页面
$topHumanPages = TrafficStatistic::getTopPages($startDate, $endDate, 10, false);// 只获取爬虫访问的热门页面
$topBotPages = TrafficStatistic::getTopPages($startDate, $endDate, 10, true);
常见问题
Q1: 为什么有些访问没有被统计?
A: 系统会自动排除以下请求:
- 管理后台和个人中心的访问
- API 路由
- 静态资源文件
- 非 GET 请求
如果您的访问路径符合以上条件,将不会被统计。
Q2: 数据多久写入一次数据库?
A: 系统每5分钟自动批量写入一次。如果需要立即写入,可以手动执行 php artisan app:batch-write-traffic-stats 命令。
Q3: 如何修改数据保留时间?
A: 有两种方式:
- 修改定时任务:编辑
routes/console.php,修改--days参数 - 手动执行:执行
php artisan app:clean-old-traffic-stats --days=天数
Q4: 爬虫识别不准确怎么办?
A: 可以修改 app/Http/Middleware/TrackTraffic.php 中的 isBot() 和 getSpiderSource() 方法,添加或修改爬虫识别规则。
Q5: 如何查看缓存中的数据?
A: 可以使用 Laravel Tinker:
php artisan tinker
然后执行:
// 查看某个时间点的队列
Cache::get('traffic:queue:2026-01-17-14-30');// 查看所有流量相关的缓存键(需要 Redis)
Redis::keys('traffic:*');
Q6: 数据量很大,会影响性能吗?
A: 系统采用了以下优化措施:
- 使用缓存暂存数据,减少数据库写入频率
- 批量写入,每5分钟写入一次
- 使用索引优化查询性能
- 自动清理过期数据,控制数据量
如果数据量仍然很大,可以考虑:
- 缩短数据保留时间
- 增加批量写入频率
- 优化数据库索引
Q7: 如何禁用流量统计?
A: 从 routes/web.php 中移除 TrackTraffic::class 中间件即可。
Q8: 可以统计其他路径吗?
A: 可以修改 app/Http/Middleware/TrackTraffic.php 中的 shouldTrack() 方法,调整过滤规则。
相关文件
- 中间件:
app/Http/Middleware/TrackTraffic.php - 批量写入任务:
app/Jobs/BatchWriteTrafficStatsJob.php - 清理命令:
app/Console/Commands/CleanOldTrafficStats.php - 数据模型:
app/Models/TrafficStatistic.php - 统计看板:
app/Filament/Manager/Pages/TrafficStatistics.php - 详细列表:
app/Filament/Manager/Resources/TrafficStatisticResource.php - 数据库迁移:
database/migrations/2026_01_17_204550_create_traffic_statistics_table.php
更新日志
2026-01-17
- ✅ 初始版本发布
- ✅ 支持真人/爬虫区分
- ✅ 支持爬虫来源识别
- ✅ 自动批量写入和清理
文档版本:1.0
最后更新:2026-01-17